There are many areas to consider with a large scale enterprise deployment of an ECM repository. Some of the main areas include:
- Performance
- High Availability
- Indexing
- Backup & restore
- Disaster Recovery
In today’s world, the content explosion has meant that many companies now struggle to manage the systems, databases, file systems and applications. Environments that were architected and built several years ago met the current needs at that time but today are struggling for resources and capacity. Architects, Service Managers or Application Owners now find themselves with the difficult decision whether to upgrade, migrate or implement a tactical solution to keep services running while keeping another eye on the big picture and strategy. It can even be a case of waiting for the business to determine their priorities and budgets for the year(s) ahead.
Performance:
One area that I have seen this repeatedly in the FileNet/CM8 world are large FileNet Object Stores or CM8 ItemTypes. Rarely there is thought given to the long-term future of these when they are initially created. Some organisations perform periodic capacity planning and can often determine when things are going to get nasty well in advance.
Since database storage is only recommended for objects smaller than 10KB and smaller quantities we can turn our attention to file storage areas. Best practices state that you shouldn’t have more than 5000 objects per file system directory and on creating a new file store object store in FileNet there are 2 options: Small and Large. In essence there difference between these is the number of folder levels created when completing the wizard interface. Small object stores create 3 levels of folders and hence tailored for less objects in comparison to large object stores with 5 levels supporting over 60 millions documents.
So how to do we tune our object stores to for optimum performance. Knowing what we have just learnt there is the ability to divide our content into a number of object stores based on the number of objects. Using storage policies we can even roll over object store use based on the number of documents added or on date ranges. With the correct capacity planning in place then physical and logical splits on ECM repositories can be planned. It is commonly a case that organizations will split content into departmental buckets due to business applications and security generally being closely linked. Other reasons to split object stores maybe retention or legally driven.
So once we have our content split into smaller logical buckets and assigned the correct storage policies to allow roll over of content in storage areas as time continues we then need to turn our attention to the complimenting database storage which holds our meta data.
Generally, the performance tuning of databases occurs once the system has been used for a period of time and the usage can be determined as it is difficult to tune a ‘green fields’ install without any content and benchmarks of the user activity. Usually, only larger companies can invest in the time, effort and cost associated in load and performance testing has taken place in advance of a project or build. As a rule of thumb reviewing those frequently called queries and long running queries can be a good place to start your database tuning. However, either of these initial testing scenarios should not be the end of the tuning activity and regular reviews should be conducted to ensure the database performance remains at an optimum and regular tweaks are made to compensate for the usage or query pattern changes that may occur due to seasonal activity and of course growth. There are various approaches for performing such load and performance reviews depending on the underlying database system. In MS SQL Server there is the Enterprise Management Studio Performance Dashboard and in IBM DB2 there are a series of system tables to help establish long running queries.
High Availability
Often High Availability, HA and Disaster Recovery, DR get confused and although different DR approaches can rely heavily on HA. Firstly, there are different levels of HA that an organization should understand before rushing into making a decision. On understanding these levels then these should be mapped to what the business SLA’s are to determine the most suitable solution.
Generally, there are 4 approaches to system fail-over:
- No Fail-over:
- Recovery Time – Unpredictable
- Cost: None to low
- User Impact: High
- Cold Fail-over:
- Recovery Time – Minutes
- Cost: Medium
- User Impact: Medium
- Warm Fail-over:
- Recovery Time – Seconds
- Cost: Medium to High
- User Impact: Low
- Hot Fail-over:
- Recovery Time: Immediate
- Cost: High
- User Impact: None
Both HA should be driven by the business and be based around their SLA’s as well as the budget deemed appropriate. It can also depends on the use case. A 24 x 7 online banking website would generally demand a hot fail-over compared to an internal holiday request system. In short, warm and hot fail-overs are not cheap to implement in large ECM systems and hence the decision to implement HA should not be taken lightly.
Indexing:
As data repositories continue to grow consideration needs to be given to the ability to search for valuable information as what use is a repository if you can find what you are looking for. Metadata searches are a relatively easy problem to tackle. As previously mentioned as metadata database grows then consideration should be given to those searches that are performed most frequently or return large result sets. There are tools on the market to assist with this but much can be achieved by using those features delivered OOTB with databases such as DB2 or MSSQL. DB2 have inbuilt IBMSYS tables to assist in determining long running queries were as MS SQL Enterprise Studio provides an easy to reporting interface which provides those most frequently ran queries as well as ranking the run time for the top 10 queries executed. DB2Explain and DB2Optimizer tools are also key tools to any DB2 DBA and should be used frequently in large deployments to ensure the system is running efficiently and tweaked as necessary with data usage and growth.
Managing keyword or content searches can be more challenging. Indexes can typically grow larger than the content it is based upon and unlike content can also very fragile. Indexing tasks are I/O intensive due to the process in generating the associated index files. Lots of temporary files are generated which can be seen as unusual activity to AV products. Ensuring AV software isn’t scanning your index directories is advisable as well as disabling Windows Indexing services. Space is also a key concern as running out of drive space during the index process is also likely to lead to a corrupt index. So we now know what to look out for or what to avoid to proactively protect our repository indexes but what if the inevitable happens? What can we do to restore our search services in the minimum amount of time to the business?
IBM FileNet’s latest version of Content Search Services, CSS has several useful features which have all matured from the early days of it being Verity or Content Search Engine, CSE after the IBM acquisition. The latest CSS provides the ability to not only schedule indexing for out of hours processing but also the ability to auto-rollover indexing area means our indexes are now broken down into manageable chunks. Having these manageable chunks mean that more flexibility and efficiency can be given to our backups, restores and DR processes.
Backup and Restore:
When does big data get too big? When you can’t restore it within your SLA’s then your data is too big and you have an even bigger problem!
The underlying components of the majority ECM system being the file system objects and corresponding databases the general approach is to ensure that these components are restored and rolled forward to a specific point in time so they are all synchronized. Obviously, in a Business Continuity, BC scenario the time to restore a service versus the data accuracy needs to be determined. This is generally dictated by the SLA with the business as an example in the case of a banking system the accuracy of data is imperative as opposed to a client services application which may be loosing new business every minute their ECM system is down.
Below is a diagram highlighting the relationship of the various components of an ECM system and the dependency on each other to be synch for a full up-to-date system restore.
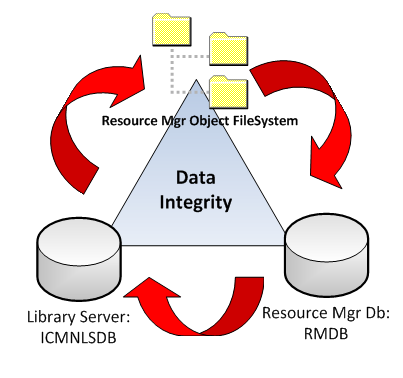
Two terms to be familiar with when it comes to backups and restore are Recovery Time Objective, RTO and Recovery Point Objective, RPO. Both these objectives should be set by the business in the business continuity plan and then the appropriate infrastructure put in place to support them. Below is a high level example of Recovery Time Objectives, RTO and Recovery Point Objectives, RPO:
|
Client Name
|
Users
|
System Usage
|
Priority Ranking
|
RTO
|
RPO
|
|
Company XYZ
|
~900
|
Document Mgmt Sys
|
2
|
4 hours
|
1 Hour
|
|
|
|
|
|
|
|
|
Sub-System
|
Priority
Ranking
|
RTO
|
RPO
|
Sub-System
Depends on
|
Sub-System
Required by
|
|
DB2
|
1
|
30 mins
|
5 mins
|
O/S &
Hardware
|
Company
XYZ
|
|
WebSphere
|
1
|
30 mins
|
0 mins
|
O/S &
Hardware
|
Company
XYZ
|
|
FileNet
|
1
|
1 hour
|
30 mins
|
WebSphere
& Storage
|
Company
XYZ
|
|
Client Lookup
|
3
|
½ day
|
½ day
|
DB2
& FileNet
|
Company
XYZ
|
It can be typical of the business to want immediate access and total up to date recovery of data but in outlining the costs that come with these demanding requests for enterprise systems then there is usually a happy medium that can be agreed upon. Once these parameters are defined then the architect needs to turn their attention on how to carve the back-end data up into manageable chunks as well as utilizing the technology to the best of its ability to provide the most efficient and up to date turn around of restored data.
Disaster Recovery:
Disaster Recovery, DR and Business Continuity, BC are often confused but have similar purposes. The difference being that DR is the continuation of a company’s vital services from a natural or human-induced catastrophe compared to BC which relates to those daily/weekly activities that take place to ensure the restoration of business functions.
Many of the same challenges that exist for high availability, backup and recovery and also indexing are true for DR due to DR procedures and plans relying on these functions. All the procedures for these functions should be brought together in a DR PlayBook which ideally should be created and walked through step by step before systems go live. However, this is seldom the case but already live ECM systems should also have DR PlayBook in place and plan to have bi-yearly/yearly DR tests scheduled during out of service hours. Enterprise systems and infrastructures are constantly changing so these scheduled tests will ensure nothing has been changed to impact your DR procedure. If it has then you can make those vital updates to the PlayBook then and test rather than discovering them during the crisis.
Summary:
Hopefully, the following has given some insight into the challenges surrounding large scale ECM deployments and the key aspects to consider and potentially how to address them although every environment is different. The one thing to consider is that a lot of these expensive head-aches and efforts go away if a cloud or potentially a hybrid (on-site/cloud) model is used. Cloud in itself is another discussion with it’s own challenges but some food for thought for now.
41.944698
-87.642441






