IBM Content Collector has had the Lists feature from it’s early versions. It provides the ability from a task route to lookup a value in the List specified and on a match then return the corresponding result. This functionality can be applied to a decision point were a rule can be ran against the list or it can be applied to the property of a new document.

More can be found here in the IBM Content Collector Infocenter.
To add more power to this feature there is the ability to apply regular expressions meaning that your lookup Lists can be dynamic. Rather than listing all the possibilities a single regular expression can be substituted to achieve a more flexible and dynamic lookup.
Below is an example of how to build regular expressions into your List lookup:
– Previously, we saw how to add a dynamic metadata lookup to setting a property value:

– If we turn our attention to the Lists section in ICC Configuration Manager

– We can add new entry as shown
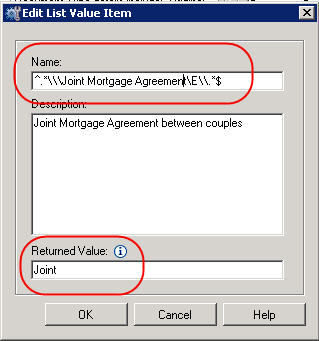
– To explain the regular expression we are reading a string that is being passed in – for example a folder structure in a shared mailbox
^ = signifies the start of the full string
$ = symbolizes the end of the full string
.* = any number and type of characters
\\ = represents a back slash or in our case a new folder
E = End of the fixed string
Out fixed string is “\Joint Mortgage Agreement\”
We can see the return value below as “Joint” – this could be passed to a rule or be used to set a property. The only limitation I have come across is it can’t be passed from setting a property value to a rule – it is either one or the other.
– But what happens if different people have named the folders differently over time?
Eg, Joint Mortgage Application or Joint Application or Joint Mortgage or Joint Applications or Joint Mortgages
Never mind all the types that can occur in older systems that don’t have mandatory fields or drop downs set for Document Categories.
We can make the foregoing more generic to ensure a higher match rate by doing the following:
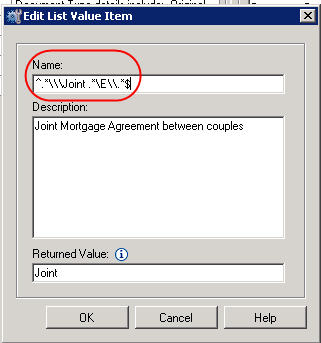
– By adding our /* we have catered for all the possible variations of folder or category name. Not full proof but it should catch the majority.
So the key takeaway is that Lists are very powerful but by adding regular expressions into your list lookup values you can add even more flexibility – so don’t think of your list as purely static values (although they can be used for this).
To give an indication of the overhead, I have ran up to 6 list lookups when setting document properties with up to 5000 regex values in the lists with little impact to performance.
Finally, I would like to thank Dan Small from IBM for all his help on this and hopefully I won’t forget all my regular expressions in the next few weeks! 🙂
41.944765
-87.642403








